Intelligent Pipeline Management with Einstein Discovery
A key pillar in the CRM landscape is pipeline management, where sales representatives track sales opportunities that progress through various stages until closure. This process results in either winning the specific sales opportunity or closing the opportunity without winning the business. The latter may be because the opportunity was lost to a competitor, because the prospect didn’t decide to purchase, or any other reason. Since its earliest days in 1999, Salesforce has supported sales organizations to orchestrate this process with its CRM product called Sales Cloud. Using techniques from Machine Learning, this process can be optimised by reinforcing the human experience and augment it with machine intelligence. This can lead to better outcomes, such as reduced time-to-close, increased win rates, increased deal sizes, and so on.
Salesforce has grouped all its Machine Learning capabilities under the brand Einstein. These include turn-key and out-of-the-box features in a specific business app. Some of those features are part of certain editions of the Sales Cloud product, others come in an add-on license called Sales Cloud Einstein. These packaged features are designed to remove all possible friction and obstacles in generating predictions and recommendations resulting from Machine Learned models. That means that they are maximally automated and that using them starts literally by switching them on by flipping a switch in the setup environment of Salesforce. This is a great capability that takes away the barrier to using Machine Learning in front-office business contexts. For this to work, however, the use of the standard Sales Cloud product is required, and when customization has been applied, the solutions may deliver less accurate results or fail to work completely. Moreover, their out-of-the-box nature limits the configurability of these Einstein features. The Salesforce admin, who is assumed to have little or no skills in working with data and machine learning, has no control over aspects such as selection of training data, choosing and creating attributes for machine learning purposes, control over model deployment, and (re)training, visibility into model accuracy, etc.
Many larger and more mature sales organizations, therefore, choose to realize these capabilities with more customizable capabilities in the Einstein portfolio. Einstein Discovery, part of the Tableau CRM platform, is designed to let the business analysts, power users, and data professionals (including data scientists and Machine Learning practitioners) train predictive models, get insight into data and orchestrate model deployment for front-office use. The differentiating capabilities and unique features within the machine learning space are well described in this whitepaper.
In this article, we will describe the benefits of using Machine Learning for opportunity scoring, and describe how to correctly set it up correctly using Einstein Discovery. Opportunity scoring – which is all about predicting the likelihood to win a sales opportunity, and it is one of the most important components of intelligent pipeline management.
The structure of this article is as follows. First, we describe the necessity of machine learning by contrasting the concept of Opportunity win likelihood is with probabilities that are manually maintained by the Sales representative, following from the sales path. Then, we describe how this opportunity scoring can be set up in Einstein Discovery, describing some common approaches we have observed in various implementations. We continue by describing how these opportunity win likelihoods can be used in different business processes, including using recommendations from the model to improve the win likelihood. We conclude by linking the opportunity scoring back to the overall concept of intelligent pipeline management.
Walking the Sales Path Way?
Note the emphasis in the introduction on the word predicting the likelihood to close, in contrast to the probability that is maintained manually by the sales rep, often following from the sales path stages that the opportunity goes through. Many businesses maintain such a sales path for opportunities in Salesforce to reflect their sales methodology. Each opportunity is matured from one stage through the next as the engagement with the customer progresses. It is a standard capability of Salesforce that any object can have a path associated to it. The sales path associated with the opportunity object can be easily configured by the Salesforce admin and may look like this for example:
- Prospection (10%),
- Qualification (20%),
- Differentiation (30%),
- Delivering proof of value (50%),
- Negotiation (80%) and
- Closure (100%).
The percentages behind these phases reflect the closing probability of that opportunity as soon as it enters that stage. This probability is then often used for forecasting purposes, to calculate a weighted or adjusted pipeline value. For example, a $100,000 opportunity in stage 3 (Differentiation – 30%), would then count for $30,000 in the weighted pipeline forecast amount. Countless businesses have run their pipelines like this and it’s a proven approach. There are however three key limitations to this approach, that Einstein Discovery can remove thanks to its no-code AI machine learning.
Limitation 1: imprecise forecast
When the sales path is set up correctly, the probabilities reflect the average win rate for opportunities in that stage. In the sales path above, only 10% of all the opportunities logged in the system are actually won (see stage 1). Some opportunities never make it to the more advanced stages. For example, when an opportunity reaches stage 4, the probability has already increased to 50%, as half of the opportunities that make it to that stage are actually won. The problem however is that we never know which half… This approach is essentially confusing average win rates and sales path progress with individual closing likelihood. Particularly when opportunity amounts differ, that may lead to an imprecise forecast. See the below example for an illustration of that point.
Suppose there are two opportunities in stage 4 (Delivering Proof of value – 50%), one Opportunity for $50,000 and one for $400,000. The weighted pipeline will then be $225,000 (half of $50,000 + $400,000). They both have a 50-50 chance of closing, based on the statistical average win rate of 50% in that stage. But what if there are good reasons to believe that the big opportunity of $400k closes, but the smaller one of $50k is a long shot, most likely lost? If indeed that happens, then the forecast is $175k too low, simply because this approach is based on averages. What if we could have a predictive model, that predicts the likelihood to close the $400k opportunity as 80% and the $50k opportunity as 20%, despite the fact that they are both in Stage 4? Then the value of the weighted pipeline would then be 0.8 * 400k + 0.2 * 50k = 330k which is much closer to reality.
Limitation 2: Lack of prioritization and alerting
Another limitation of the standard sales path probabilities is that they don’t provide any focus or prioritization to the salesperson. Let’s examine the above example again; what if the sales rep wasn’t very aware that the $50k was such a long shot, and spent a lot of time on it? Perhaps even to the extent of neglecting the valuable $400k opportunity, resulting in its loss. That costly loss could easily have been avoided by using a deployed Einstein Discovery model that scores the opportunities and showed to the user that the $50k opportunity was unlikely to close and should not get so much focus.
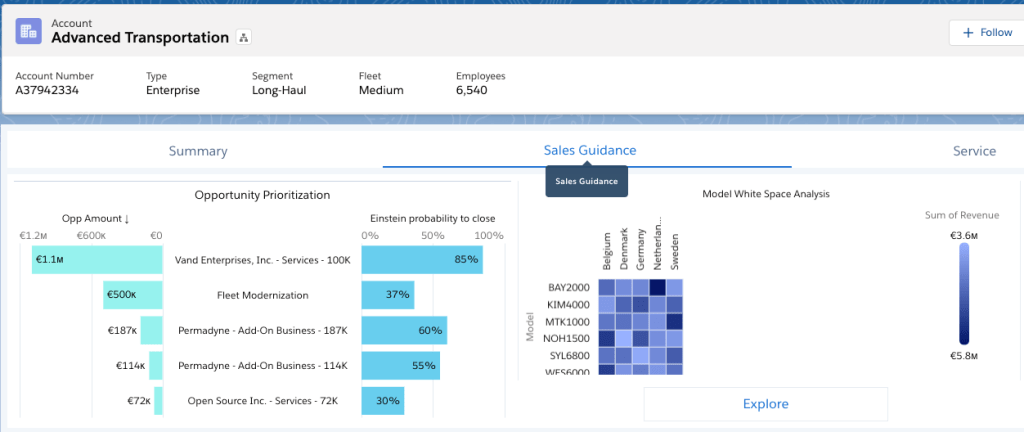
The alerting using likelihood to close works also the other way around. See the above screenshot for an example, where we see the opportunities for one account, ranked by the amount and enriched with the Einstein propensity to close. Immediately the rep’s attention gets drawn to the 500k opportunity with only 37% to close. Such a large opportunity requires inspection; a large portion of our pipeline depends on it; what can be done to improve its likelihood to close? With only stage probabilities coming from the sales path, that may have easily escaped the sales rep’s attention.
Limitation 3: No guidance
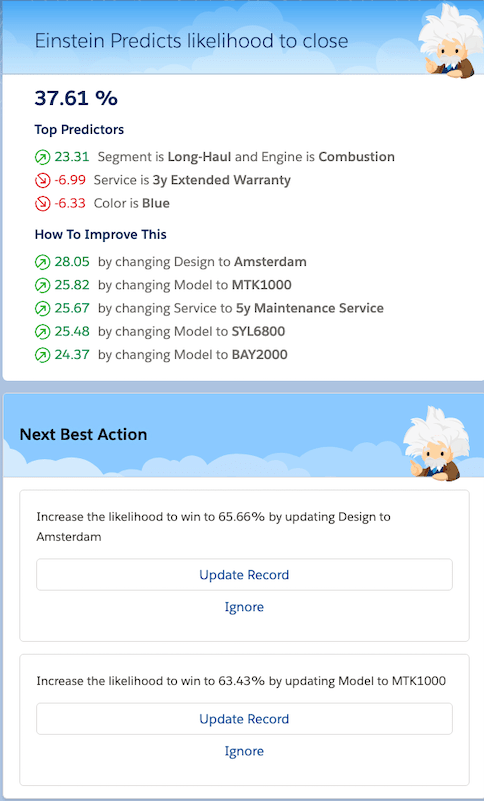
Opportunity sales paths are often complemented with “criteria for success”, which are often milestones that need to be met before an opportunity can be progressed to the next stage. These are a reflection of best practices in the sales team and act at the same time as qualification criteria for the various stages. It’s good to structure the methodology like that. In reality, it’s almost never sufficient though; as every opportunity will have its own challenges and obstacles to overcome to increase its true likelihood of closing. Machine Learning models can offer more precise and targeted recommendations to advance an opportunity than the ”one-size-fits-all“ success guidance from the sales path. What may be a crucial step for one opportunity, may not be important or even counterproductive to the next. These individual subtleties can be picked up by Einstein Discovery and surfaced to the sales rep, like in this screenshot to the left, which shows embedded components from an opportunity page.
Discover the true closing likelihood with Discovery
So Machine Learning models offer a more precise prediction of the probability to win and even show recommendations to improve the likelihood. But how do you set up such a predictive approach using Einstein Discovery? In this blog, Product Manager Bobby Brill explains how to prepare data for another related prediction, i.e. the predict the time to close the opportunity. Similar concepts apply to the closing likelihood prediction, however, I will expand on some subtleties here.
Selecting the training data and specifying the Einstein Story formulation
To train a model, Discovery needs to learn from historic data, and that means closed opportunities. These can be either won or lost, but they can’t be open. If it’s not clear yet whether it will be a won or lost opportunity, how can Einstein Discovery learn from it? So firstly we need to filter the training data down to closed opportunities only.
That gives you a set of opportunities to train on, and the formulation of the Story will be either to “MinimizeClosed(Lost) in Opportunities” or to “MaximizeClosed(Won) in Opportunities”. The predictive model will be pretty much the same in both cases. Their difference is mainly in the direction of the score (and the corresponding text in the generated Story insights).

- In the case of “Maximize Closed(Won) in Opportunities” like here on the right, the model predicts the likelihood to win. The closer the score is to 1, the more confident Einstein is that the opportunity will be won, so a high score is a good thing here.
- In the case of “Minimize Closed(Lost) in Opportunities” the model predicts the likelihood to lose. The closer the score is to 1, the more confident Einstein is that the opportunity will be lost, so here a low score is a good thing.
Note that Maximize Closed(Won) is probably the most intuitive for users, but we wanted to describe the symmetry between these two Story formulations for reasons of completeness.
Besides closed opportunities, should you add more filters to the training dataset? In general, larger training datasets give better (more accurate) results, but not to every extent. For example, are opportunities from five years ago still representative of the market that your business currently operates in? You may wonder if you actually want the model to learn from such old wins and losses. Also, it may be that you end up not creating one opportunity scoring model, but multiple. There are a couple of reasons to decide for multiple models instead of one, and this is very well explained by Olfa Kharrat in this blog.
Specific to opportunity scoring, there is another reason to split the system into multiple models; it’s often advised to train one model per stage from the sales path. I will get back to that later in this article.
Adding predictors to the model
So we have selected the training data, now what about predictors to learn from? What are some of the key characteristics that are indicative of a won or lost opportunity, that the model should pick up? Clearly, fields from the account and the opportunity are key here. As an example, take the Story configuration as shown below:
Attributes from the account and Opportunity have been chosen as predictors in the model.

Note that there are some special fields like “Acc Seniority”, or “Product Seniority”. These are numeric fields, calculated as the difference between the account or product creation date, and today. Converting dates to numeric fields like that is often a good idea. The reason is that the product or account creation date by itself is not really impacting the closing likelihood, but the time that this Product or Account has been around does.
Such a model can already produce somewhat accurate predictions. As you may know, Einstein Discovery evaluates the predictions using a validation set and calculates performance metrics. If those are new concepts, I recommend reading a blog on how to measure the accuracy of a classification model here.
To the right we see the confusion matrix and the common metrics for the model above. You can see that roughly 75% of the predictions are correct using this model!


Now the question is, can this model still be improved? What additional predictors can we bring to the model to improve the accuracy? As any sales rep will be able to confirm, a lot can be learned from the speed with which the opportunity passes through the stages. For example, a deal that went very quickly through the “Qualification” stage, but stuck for a very long time in the ‘Delivering proof of value“ stage, may be not very well framed and may be more difficult to close. Or a deal that is very long in the ”Negotiation” stage, may have a lower chance of closing even if it survived that stage; it may be one of those unfortunate opportunities that bounces at the very last moment.
Therefore, the number of days that an opportunity spends in a certain phase are likely good predictors. Also, it may happen that an opportunity is set back a certain phase instead of making only progress. The number of times that an opportunity entered a certain phase is also very indicative therefore. Thanks to the opportunity history that is maintained by Salesforce, we can add those fields, and the Story setup becomes something like what we see on the left.
Let’s run this model, and take a look at the performance metrics. They are visualized on the right here.
Amazing results! Take a look at those metrics, the prediction errors have reduced dramatically. In more than 90% of the cases, Einstein now predicts correctly whether the opportunity will win or close. That’s spectacular!
But wait a minute, isn’t that even too good to be true? Let’s think it over.

Removing Hindsight bias for Opportunity Stages
Our training data still contains all the opportunities. Some of those opportunities never made it to the later stages, like “Proof of value” and “Negotiate”. If an opportunity never made it to Stage 5 “Negotiate”, then it will have spent 0 days in that stage, and it will also have arrived in that stage 0 times. So in reality the fact that the opportunity was lost, is implicitly present in the data thanks to those 0 values for those fields. When we want to deploy this model and score an opportunity that is still in phase 3, we of course don’t know yet that it may never reach this stage (which is why we are scoring in the first place). This concept is referred to as “Data Leakage” by data scientists, or sometimes referred to as “Hindsight Bias”. How do we get rid of this?
Hindsight bias refers to introducing data in the training set, that contains in some way the very thing that you are trying to predict. This implies you also have this information when you are creating the prediction later on using a model deployment, which is clearly not the case. Essentially, you are introducing a bias in the model by adding information that you only can know in Hindsight, hence the name Hindsight bias.
One way of resolving this problem is by creating a separate model for each stage. Suppose that we want to predict the likelihood for opportunities in stage 5, “Negotiation”. Stage velocity attributes (the number of days and times in each stages) can then only be included up until stage 4. Moreover, opportunities that never made it to stage 5 are not allowed to be part of the training phase for this stage 5 model. Likewise, the training dataset for the model that scores stage 4 opportunities, can only include stage velocity data and opportunities up until stage 3, and so forth. Let’s create 3 models, for stage 3, 4 and 5 respectively, and compare their results.

The results are clearly interpretable; the further an Opportunity progresses, the more accurate the corresponding model predicts its probability to win. This is what we would expect; those models take advantage of the data that’s contained in those Stage velocity attributes, without misusing them as hindsight bias. Also, this notion in general aligns with our intuition that the earlier-stage opportunities are simply harder to predict correctly.
Improving the models for early stages: leveraging historic win rates
Predicting opportunities in stage 4 and stage 5 correctly is valuable. Think about the three limitations of manual probabilities that I started with (imprecise forecast, lack of focus and lack of guidance). Being able to overcome those limitations for later stages has a lot of positive business implications. Even more valuable is overcoming those limitations at earlier stages of the opportunity life cycle. That is however also more difficult. To avoid hindsight bias, we can only use limited data regarding stage velocity. The simple matter is that in early stages, less information is known about the opportunity that can be leveraged to create a good predictive model. That’s where some creativity and data manipulation can help to increase the accuracy significantly.
Good indicators for success, are past wins and losses in similar situations. For example, we can add a column that reflects the historic win rate that we observe for that account. This may seem like hindsight bias too, but it isn’t in reality. When predicting the probability to close for a certain opportunity, it’s perfectly justifiable to use the historic win rate in that account; it’s simply a field we can calculate when obtaining the score. Similarly, historic win rates in the territory or even with the specific opportunity can contribute significantly to the accuracy of the model.
Attributes like historic win rates per account or per product are typically not maintained as fields on the corresponding objects in Salesforce. That is not a problem, they can easily be created in Tableau CRM using aggregation capabilities in recipes and store them at the right level in data sets to be used in training. When the model gets deployed and the fields are mapped to Story columns, you then make use of the hybrid field mapping. This maps some of the Story columns to the Salesforce object fields (e.g. Industry, Region etc.) and some of the Story columns to data set fields (e.g. historic win rate per account). When an opportunity gets scored, that means that the data set fields that are used to obtain the score are only as up to date as the latest data flow or recipe run that calculates them. In this case that is not an issue, because we use the mechanism for fields that don’t change on a very frequent basis anyway, and the frequency of data flow and recipe runs can easily keep up with keeping the historic win rates up to date.
Conclusion
There are many advantages to orchestrating intelligent pipeline management with the help of Machine Learning, and in this article, I discussed some best practices of how to set that up with Einstein Discovery. I purposely focused on the creation of the models, as these are key to overcoming the key limitations of having manual probabilities only (imprecise forecast, lack of focus, and lack of guidance). To obtain truly intelligent applications, it is essential to use these models in harmony with the business process that’s being operated; i.e. to deploy the models and consume their outcomes in the CRM. Please check out some further articles, like The complete guide to Einstein Discovery model deployments or Create intelligent applications with the Predict node in Recipes. The combination of easy-to-setup predictive models and native deployments in salesforce is really powerful. So please let us know; how will you leverage Einstein Discovery to make your pipeline management more intelligent?