Predicting the best up-sell with Einstein Discovery Multiclass models
Exciting news: with the Spring 22 release, Einstein Discovery supports multiclass classification predictions (Generally Available). This allows you to solve even more predictive use cases for your business with Einstein Discovery. With these Multiclass models, you can predict probable outcomes among up to 10 categories. For example, a manufacturer can predict, based on customer attributes, which of five different service contracts a customer is most likely to choose.
Multiclass models form an important addition to the model types that Einstein Discovery already supports (regression / numeric predictions and binary classification predictions). Let’s see a few use case examples for all three model types of Einstein Discovery:
- Numeric Predictions (regression): analyze and predict a quantity. Example use cases include:
- Predicted Amount of an Opportunity
- Predicted Time-to-Close of an Opportunity
- Predicted Customer Lifetime Value of an Account
- Predicted Customer Satisfaction of a Case
- Binary Classification analyzes and predicts a probability of a record belonging to one of two classes, e.g. the probability of true / false, or won / loss, or yes / no etc. These often have to do with predicting the probable outcome of an event. Example use cases include:
- Predict the probability to win an Opportunity
- Predict the probability for an Account to buy a specific Product
- Predict the probability a Lead will convert
- Predict the probability an Account will churn
- Multiclass Classification (Generally Available in Spring ‘22!). This predicts the probability of a record belonging to one of three to up to ten classes! The model returns multiple probabilities for one record, i.e. one probability per possible class. Example use cases include:
- Predict the most likely up-sell / cross sell for an Opportunity
- Predict the most likely next phase for an Opportunity
- Predict the most likely case reason
- Predict the most likely account segment
Let’s look at the specific use case of up-selling service contracts on an Opportunity. For this purpose, we will consider Pelican Trucks, an imaginary manufacturer of trucks, that sells vehicles (such as delivery trucks) to logistics providers. In addition to vehicle sales, the company sells service contracts. That means from a data model perspective that the Opportunity has a lookup to a single Contract record. In other contexts, this can be different data, such as a lookup to consumables or other provided services. There are five different service contracts that Pelican Trucks offers, as shown in the following lens on one of Pelican Trucks’ datasets:
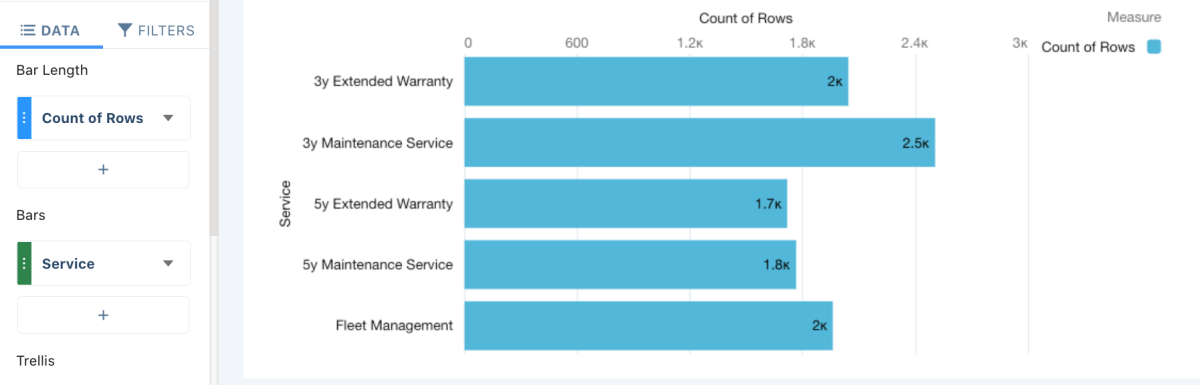
This lens shows a dataset with 10,000 closed Opportunities (both won and lost). It has been grouped by the Service Contract that was offered for those Opportunities. The contract types are ranked by their value: ‘3y Extended Warranty’ is the most basic service contract, and ‘Fleet Management’ is the most comprehensive service offering. Pelican Trucks would now like to train a model to predict the most likely Service Contract that a customer will choose when they purchase vehicles. Such a model can advise their Sales Reps about which contract they should offer to their customers – directly on the Opportunity page, as shown below:

This Opportunity is currently in the negotiation stage. The Sales Rep can immediately see that the customer is most likely to choose the ‘5y Maintenance Service’ contract, followed closely by ‘3y Maintenance Service’ . However, the Sales Rep also sees that the high-valued ‘Fleet Management’ is third in the list of ranked probabilities, with still a 22% probability. Thanks to this insight, the sales rep can now discuss confidently with the customer about the five-year maintenance contract, and even try to up-sell to Fleet Management!
Let’s see how to build such a Multiclass model in Einstein Discovery.
Creating a Multiclass Story

As always, we begin by creating a Story. New in Spring ‘22 is that dimensions with up to 10 unique values are available for analysis. Here we have selected ‘Service’ (with 5 unique values) because we want to predict the most likely Service Contract. Note that the “Minimize” or “Maximize” options have now disappeared. Why? For a multi-outcome field, we don’t always have an order or preference. We are simply predicting what is the most likely class for each record.
We then have the same options as with any other Story: we can generate Insights Only (without a predictive model), or to train a model for Insights & Predictions. Also, we can choose between autopilot mode or manual mode. I select “Insights & Predictions” and Manual mode because I want to edit some model configurations in the Story Settings overview. Note that all the familiar Story configuration options are available to Multiclass models as well.

I want to make two specific changes.
- First, the Sales Reps sometimes forget to maintain pricing information on the Opportunity. Therefore, I apply a “Replace Missing Values” transformation to that column. If a Price field is left blank, Einstein Discovery will now replace that blank value with the average price for that Model. This may not be always 100% accurate, but it is definitely better than not using any price information at all. This transformation applies both to training as well as prediction time.
- Second, I apply a filter to the Stage column. This is because I want to train the model only on Opportunities that are actually Won. After all, it’s only for these won Opportunities that I can be fully sure that the customer actually selected the corresponding Service Contract. Perhaps some of those Lost Opportunities were actually lost because we were offering the wrong Service Contract type! Therefore, I exclude the rows with “Stage = Closed Lost“ from the story. Note that I have selected ‘Exclude deselected values’ in the Settings. Otherwise, these rows are still part of the training data but grouped in a so-called ‘Other’ bucket.
Now I’m ready to create the Story and start exploring the insights.
Exploring a Multiclass Insights in the Story

Some parts of the Story are very familiar, and some Multiclass insights look a bit different when compared to insights for binary classification or regression stories. The Summary Insights look the same (what Service type occurred the most, and what Service type occurred the least), as well as the Fields panel that shows all of the variable correlations to the outcome.
In this case, we see that Fleet Management is offered most frequently, especially when combined with a special service called ‘Driver Development’. In this case, our expert instructors train our customers’ drivers in the special features of our trucks. Also, this ‘Driver Development’ happens to be a very strongly correlated predictor that plays an important role in the model. Let’s analyze that a bit further. As we do so, we find some insights that look different for Multiclass Stories.

The first insight we find (as shown above) analyzes the Service Contracts in combination with whether or not Driver Development is offered. It’s no surprise that this is a Top Insight, based on the above summary insights!
We can see that when we offer Driver Development, Fleet Management is sold 38% of the time (left bar chart). However, when we do not offer Driver Development, we sell Fleet Management only 21% of the time (right bar chart)! The impact of Driver Development is much smaller on the rate of occurrence for the other Service Contract types. (For 5y Extended Warranty, it’s even the same: 20% in both cases – with or without driver development.)
Although the chart so far shows that selling Fleet Management is strongly driven by offering Driver Development, it’s not very clear yet what this means for the other Contract Types. Thankfully, I can change a setting for this chart to reveal this pattern even stronger. To do so, it is possible to toggle this chart from “Proportions” to “Difference in Proportions”. This reveals the following insight:

On the left, for Fleet Management, we see a bar of 17. On the right, we see a bar of -17. The reason for these values is that this contract type is sold in 38% of the times when Driver Development = true (left), but only in 21% of the times when Driver Development = false (right). The net difference is 17 percent points. In this chart, we see in one glance how these Service Contract types depend on the other Account and Opportunity characteristics.

This insight type is available for all descriptive insights in a Multiclass Story, even for second-order insights in which the combination of two variables is used to explain the Service Contract type!
In our example case, however, this has not resulted in significant insights (all bars are grey), because my dataset is too small for analysis at this low granularity. So what I’m seeing are actual differences in class proportions that exist in my dataset. Fortunately, Einstein Discovery warns me that these differences aren’t actually statistically significant.
Diagnostic and Comparative insights (shown in Waterfall charts) are also available for Multiclass stories.

In the above example, we see an insight that explains all drivers behind closing a Fleet Management contract when also providing Driver Development. When we investigate this insight, we discovery that it is particularly driven by Driver Development in Red vehicles (we do know that we provide this training often to our Fire brigade customers!). However, it is actually worsened by offering driver development in Finland or in the Construction Segment.
In summary, the Story experience provides a rich experience to understand, in detail, what goes on in our business. In this case, we discover insights into closing different Service contract types when we sell our vehicles. However, I want to go a step further than that and actually deploy the model to generate predictions for our end users. But before doing so, I need to be sure that the model is sufficiently accurate, so I’m going to inspect the model first!
Inspecting a Multiclass Model
To inspect the quality of a model, we move over to the ‘Model’ section of the Story, and then we land on the Overview page.

Here we see the overall quality of the model expressed in AUC (Area Under the Curve). This metric, which is widely used for binary classification models (and is explained here), tells us how well the model can differentiate between two classes – not five. Therefore, in this page, we can select each class to see its individual AUC. Because AUC is a metric that typically expresses how well the model differentiates between two classes, this means that these individual AUC’s are calculated for the separation between the individual class and the all the rest – i.e. the four other classes in this case. So, in this case, we see that the quality of the model for ‘3y Extended Warranty’ is 0.89, and we can check the five classes like that by using the dropdown.
That same dropdown is available when we go into the details of “Model Evaluation”, which shows the ROC curve, the confusion matrix, and the detailed metrics for prediction quality for each of the five classes.
It’s a good practice to go one by one through these classes and inspect model quality for each, thereby verifying that the model is sufficiently accurate across all the classes before deploying it.

A new model evaluation chart was added specifically for Multiclass models: the confusion matrix across all classes. Like the normal confusion matrix, it compares the Predicted class to the Actual class. For multiclass models, it performs that evaluation using all classes at once, and shows the results as a colored heat map. Again, we want the diagonal to be close to one, because then the model is doing a good job predicting the correct class.

Here on the left we see the confusion matrix for all classes for our example. The darkest blue is on the diagonal, which is exactly what we want to see: it means that most of the time, the model is making the correct prediction.
We also see some darker blue in the top left corner not on the diagonal, which reveals when the model makes some prediction mistakes. For example, sometimes the model is predicting ‘3y Maintenance Service’ when the actual contract type was ‘3y Maintenance Service’. That is understandable, though, because those Service Contract types are somewhat similar. Thankfully, it almost never predicts ‘Fleet Management’ when the actual Service Contract was only ‘3y Extended Warranty!’
Similarly, we see some darker blue outside of the diagonal in the bottom right corner. In this case, the model is sometimes confused between the different higher value contract types. Again, it almost never mistakes a high value for a very low value contract, which is great! Based on this review, I’m satisfied that this model is now ready to deploy into Salesforce.
Deploying a Multiclass model
The steps to deploy a Multiclass model are largely similar to deploying any Einstein Discovery model. Therefore, I won’t go into all details – it’s well described here. For now I will just say that – as always – we:
- Choose to create a new Prediction Definition, or add the model deployment to an existing one
- Choose to connect the model to a Salesforce object (and select it) or not connect it
- Map the model fields, if the model is connected to a Salesforce Object
- Segment the data, if the model applies to a subset of the data only
- Review the settings before deploying.
Deploying a Multiclass model differs from deploying a Binary Classification or a Regression model in the following ways:
- There are no actionable variables for multiclass models. Remember that I didn’t specify whether the Story should ‘Minimize’ or ‘Maximize’ when I set it up. This is because, in a Multiclass context, we often don’t know which of the classes is actually preferred. There may not be a sequence at all. Hence, we also don’t have a notion of actionable variables, because the model doesn’t know what to recommend, as it simply doesn’t know ‘what good looks like’. For each record, a Multiclass model purely predicts the probability of belonging to the different classes.
- There is no Einstein Prediction Field for multiclass models. Currently, the Einstein Prediction Field type doesn’t support multiclass predictions, so you cannot create one when deploying a multiclass model.
When the deployment is created, it’s time to use the model outcomes in the business. There are many different ways (more than 10!) to consume predictions coming from Einstein Discovery models, as described here. At the moment there are three ways to utilize a prediction from a Multiclass model in business processes:
- In the standard Einstein Predictions Lightning Component, as shown at the beginning of this article (without storing the prediction in an Einstein Prediction Field)
- Using Data Recipes, where the Einstein Discovery Predict node will store the most likely class in the resulting dataset, together (if selected) with the Top Predictors. The results can then be embedded in TCRM dashboards, or written directly to Salesforce (and beyond) using the output connector.
- Using Salesforce Flows, where the Einstein Discovery Action node will surface the most likely class to the Flow, to facilitate process automation (like automatic queue assignment, Next Best Action, etc.).



Further Use Cases
Multiclass models add a variety of new use cases to possible Einstein Discovery solutions for your business. Speaking in Salesforce terms, it allows for the prediction of any picklist field with up to 10 values. In this article, I showed how to create an up-sell model for existing Opportunities, predicting the most likely Service Contract a customer will choose when making a purchase of vehicles. This is just one example of the many variations of cross-sell, up-sell, and propensity-to-buy models that this new model type facilitates.
Here are some further use case examples to inspire you:
- Sales: The most likely next phase for an Opportunity. Opportunities don’t always flow through the stages linearly, but often circle back, or sometimes even jump a stage. When predicting the most likely next stage for an Opportunity, we get valuable information about the close likelihood and time to close for that Opportunity!
- Sales: Account Tier / Segment. Many companies maintain some form of classification or segmentation of their Accounts. Sometimes, for example when new Accounts are created, this information may not yet be present. With multiclass models, Einstein Discovery can predict it.
- Sales: Lead Quality / Type. Sometimes it’s not advisable to predict the likelihood to convert for a Lead, but to directly classify the Lead into a quality class or type, such as Hot, Warm, or Cold.
- Service: Case Type. There is almost always a case typology maintained in any service context. Einstein Discovery multiclass models can consider all the Case and Account information and classify the case into the right type. This is especially powerful in combination with the NLP transformations, such as Sentiment Analysis (GA) and Free Text Clustering (Pilot in Spring 22) that extracts keywords from a text snippet!
- Service: Case Queue, Severity or Resolution. Similar to predicting the Case Type, it is possible thanks to the generic model structure of Einstein Discovery to predict the right Queue, Severity, or Resolution for an incoming case.
- Data quality: When users omit to fill out values for (non-mandatory) fields, specifically pick list fields, you can use Einstein Discovery to predict what the most likely value for a given record is and populate it! This is especially valuable when the data is really important. Imagine the delight to users when Einstein Discovery fills out those missing values automatically, or when all the user has to do is inspect and approve the suggestion!
What use cases will you solve for with this new capability?
Excellent article! Small comment regarding the ‘Inspecting a Multiclass Model’ you say:
For example, sometimes the model is predicting ‘3y Maintenance Service’ when the actual contract type was ‘3y Maintenance Service’. That is understandable, though, because those Service Contract types are somewhat similar.
I believe you mean 3 yr Extended Warranty.
All the best!