Maintaining Data Sync and Data Prep Considerations – Data Orchestration Part 5
This blog is part of the Data Orchestration blog series. Data sync should be maintained as your requirement and environment evolved. In this part, we are highlighting the important elements of maintaining data sync. Next, we a taking a closer look at data prep tools (dataflow and recipe), their limits, and scheduling of data prep.
Maintaining Your Data Sync
We have talked a lot about data sync and the importance of governance limits when setting it up. However, as you continue with new requirements for data analysis and reevaluating old requirements any analytics developer should make sure to maintain a proper setup of the data sync.
Removing Fields
When we start creating dataflows and recipes, there are bound to be instances where we have to make changes to the fields and objects which are required as part of the dataset. Requirements change and we might later decide to remove certain fields or add certain fields to the dataset, hence we make the changes in the dataflow or recipe of the corresponding dataset.
When we remove a field from the dataflow, we must ensure that we are removing the same field from the object sync as well, as we do not want to sync fields, which we do not need in our datasets. Removing fields and objects that are no longer needed has the benefit of making the data sync run faster. Note you can only remove the field from the data sync if it is not being referenced in other dataflows. Therefore whenever you are removing fields from the dataflow or recipe regardless of the reason, you should extend the dame action to the data sync if it’s not referenced in any other dataflow.
Adding Fields
In the scenarios where we need to add a new field into a dataset, we should of course add it to the dataflow or recipe that registers the dataset. Speaking of adding the field to a dataflow, we do not need to add that field to the data sync first as the field automatically gets added to the object sync fields once included in a dataflow digest node. However, in the case of adding a new field to a recipe, we must ensure that the required field is first added as part of the data sync before it can be included in a recipe.
Ownership of Dataflows and Recipes
When it comes to dataflow and recipes the most important step for any organization with Tableau CRM is to assign an owner to a dataflow or recipe. Having a specific owner for a dataflow or recipe would ensure that there is one person to address the important tasks of maintaining the dataflow fields as well as the security of the data. Hence the owner of the dataflow or recipe should know the fields that are required to be in the final dataset, who should have access to the dataset including row-level security, what should be the schedule of the dataflow and the refresh rates of the dataset(s). There are bound to be situations where there are new requirements and new fields should be added to the dataset, but there will also be scenarios where fields are no longer needed and should be removed. Hence having an owner for a dataflow or recipe is crucial to ensure proper maintenance.

Data Prep in Tableau CRM
Once we have established a data connection to the source data, decided on a connection’s frequency for the data refresh, chosen the right set of fields from the objects, and finally filtered the data from the objects to ensure that we have the data we need for our analysis we move to the next step of making datasets available, which is creating dataflows or recipes.
What are Dataflows and Recipes?
Dataflows and recipes are tools to prep your datasets. They are essentially a set of instructions for conducting transformations on the data available in the Tableau CRM cache data. These transformations are done on the raw cached data before we store this data as a dataset for our analysis in dashboards.
Note: Check the Salesforce help documentation on how to create datasets using dataflows and recipes.
Dataflows and recipes are valuable tools that help us to make simple and advanced transformations to the data before we can use the data for analysis.
An example of how we can transform our data could be that you have Account information coming from the SFDC_Local connection and Quota data could be coming from AWS or Snowflake. Using a dataflow or recipe we can create a dataset that contains both Account and Quota information in a single dataset.
Note: Check the Salesforce help documentation for information on available transformations for analytics dataflows.
Dataflow or Recipe
I guess you might be asking a fundamental question right about now: why do we have two tools to transform data in Tableau CRM?
Well, dataflow is the legacy way of transforming our data while recipes are data prep reinvented keeping both transformation possibilities and usability in mind. The goal from the Tableau CRM product team is to eventually move to just one tool Data Prep aka Recipes 3.0.
Note: Data prep and recipe are often used interchangeably in Tableau CRM.
While we are in this phase of improving the recipe and making the same options as dataflow available, we can make use of dataflows as well as recipes. This of course raises the question: should I use dataflow or recipe?
Should I Use Dataflow or Recipe?
The answer is you can use both, but your use case will probably determine which you pick. We will talk about how we can use dataflows and recipes together as we discuss further.
As you can imagine dataflow and recipe have their own unique set of transformations available to transform your data. Over time recipes are close to closing the functionality gap to dataflow and even offer transformations not available in dataflow including smart transformations and multiple types of data joins. Check the below image for highlights on dataflow vs. recipe.

Note: Check the Salesforce help documentation for a feature comparison of dataflow and data prep.
Governance Limits for Dataflows and Recipes
As mentioned in part 2 of this blog series, when we sync the data into Tableau CRM, the data is not stored yet. We would need to run dataflows or recipes to first prep the synced data and then store it as a dataset. If we are setting a data sync to run every 15 min, we would typically expect to schedule the dataflows to run every 15 min as well. Else we could question why we would refresh the cached data if it’s not to be used in a dataflow or recipe. However, even though we technically are able to set up the same interval as for the data sync, we should be aware of certain governance limits before we schedule our dataflows to run every 15 min.
- The maximum number of dataflow and recipe runs in a rolling 24-hour period: 60.
- Dataflow and recipe runs that take less than 2 minutes (and data sync) don’t count toward this 24-hour run limit. However, if you reach the 24-hour run limit, you can’t run any dataflow, recipe, or data sync job, regardless of size until more runs have freed up.
Let’s Do the Math
If we were to schedule one dataflow to run every 15 min, we will after 15 hours hit the limit of 60 dataflows and recipes that can be run within a rolling 24 hours period. And this doesn’t take into account if other dataflows are running and using the limits as well. Plus there is a chance of dataflow runs being canceled if they take more than 15 min to run, as Tableau CRM will not run a dataflow that is currently running.
So although we have the power to schedule a data sync and run dataflow or recipe every 15 minutes, we must use this feature with caution if we do not want to hit the governance limits.
Running Dataflows and Recipes
Once we have created our dataflows and recipes, the next step is to run them to ensure fresh data ready for analysis. However, one thing to remember before we run these dataflows and recipes is to ensure that the data sync for the objects being referred in the dataflow and recipe are freshly synced else we would end up looking at stale data. In other words, your dataflow and recipe run should occur after the completion of the connector data sync.
Note: The maximum number of dataflows you can create with data sync enabled is 100 and the maximum number of objects you can create with data sync enabled is 100. See the Salesforce help documentation for all the dataflow limits.
There are two ways to run your dataflows and recipes:
- Run them manually: This option is pretty straightforward. When we click on “Run Now”, these instructions will be run right away and the dataset would be created or updated after the run has completed.
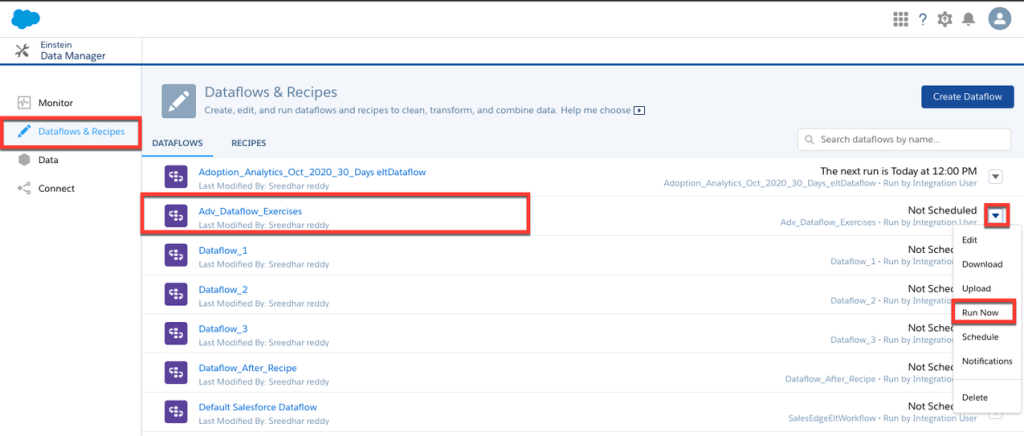
Note: See the Salesforce help documentation on how to run dataflows or recipes manually.
- Schedule them: Set up a schedule via the drop-down and the instructions will be run as per the schedule definitions. With scheduling, there are two ways to schedule these dataflows and recipes, which we will in the next two sections.

Note: See the Salesforce help documentation on how to schedule dataflows or recipes.
Event-Based Scheduling
First of all, it is important to note that event-based scheduling is only applicable for dataflows and recipes which refer to objects from SFDC_Local connection or are dependent upon other dataflows and recipes for inputs(edgemarts/datasets). In the case where the dataflow or recipe is using the local connector, dataflow or recipe, there is an option to automatically run the dataflow or recipe as soon as the data sync/dataflow/recipe for the objects/datasets that are referred to is complete.
If the dataflow contains a mix of objects from SFDC_Local as well as other data sources we will not be able to use the event-based scheduling. In these scenarios, we will have to set a time-based schedule, which we will cover in more detail in the next section of this blog.
In cases where we have a dataflow that refers to objects in two different SFDC local connections, both of the local connections need to complete their run for the dataflow run to trigger when using event-based scheduling.
Let’s illustrate the event-based scheduling option with an example. If the data sync is scheduled for 10:00 AM and the data sync is complete by 10:10 AM, the dataflow which is scheduled as event-based would start to run at 10:10 AM. Hence there is no need to guess the time it takes for the data sync to be done, the dataflow automatically gets triggered as soon as the data sync is done.

Note: You can have the following scenarios for event-based scheduling:
- After salesforce local connections sync – Considers only local connection(s)
- After selected recipe(s) and/or dataflow(s) run – You can add multiple dataflows and/or recipes to the create the dependency
- After salesforce local connection(s), dataflow(s) and/or recipe(s) sync – Considers only local connection(s). You can add multiple dataflows and/or recipes to the create the dependency
Time-Based Scheduling
As the name suggests, this option allows us to define a specific time to run the dataflow or recipe and once the run has completed successfully the dataset gets created.
As mentioned earlier, it is important that we ensure that the data sync for the objects that are being referred to in the dataflow or recipe is completed before the dataflow runs. Hence while scheduling the dataflow or recipe we need to account for the time the data sync takes and set up the schedule accordingly.


In summary, when using time-based scheduling there are a few things to keep in mind:
- Ensure that the data sync is completed
- Before we schedule the dataflow, we should know the approximate time for the data sync to be complete, which you can find by checking timings in the data monitor
- Set the scheduled time while keeping in mind the time it takes to complete the data sync.
If the data sync is complete at 10:50 AM, we need to schedule the dataflow to run after 10:50 AM, lets say we schedule it to run at 11:00 AM. Once the dataflow is run successfully, the resulting dataset would have the latest data. It is important to ensure that the dataflow is run only after the data sync is complete else the dataset would not have the latest data.

In the next part of this blog series, we will look at some additional considerations and obstacles you may encounter when scheduling your dataflows and recipes. Or head back to review the other blogs in the Data Orchestration blog series.