Create a Segmented Machine Learning Model with Einstein Discovery
It is often the case with machine learning predictive models that you need to create a model for customer data that spans a variety of “segments” in your business. The business objective (outcome variable) that you wish to apply machine learning may actually be exactly the same across all these segments – even though the segments themselves may operate quite differently in reality. The segments in your business could be – geography, line of business, customer type or size, product category, and countless other examples. Example use cases within these segments include opportunity scoring, lead/account scoring, churn/attrition, customer support predictions, and many more.
It is a common requirement to build and deploy segmented models so that the scores and insights are appropriate, relevant, and actionable for each data segment. Your reasons might include one or more of the following:
- The requirement for each model to accurately represent the relationship between the predictor and the outcome variables (specific to each segment)
- The necessity to create unique feature engineering for each segment that allows for different feature sets in the models
- A need to deploy segmented models to the same prediction fields and/or process automation in Salesforce
- Each segment may need to have different actionable variables so that the model gives users appropriate recommendations for improvement
- The segments may require somewhat different training datasets for various segments of your business
As you can imagine, attempting to operationalize segmented ML models can quickly get very messy without the right strategy. Fortunately, Einstein Discovery (along with CRM Analytics) has an elegant, no-code solution for this common challenge. There are three primary mechanisms you will need to configure in your ML pipeline to solve this business requirement:
- Recipes in CRM Analytics to create the training datasets for each segment and perform any required feature engineering
- Segmentation Filters in the Einstein Discovery deployment wizard
- Deploying multiple models to a common Prediction Definition (*Please note that it is also possible to deploy a single model to multiple prediction definitions. This architectural approach may be very useful in other scenarios.)
Let’s look at a working example of how to tackle this challenge with a fictional company named Pelican Manufacturing. They manufacture a variety of large fleet vehicles that are used by customers in transportation, emergency services, construction, etc.
Note: This walk-through is just one approach to model segmentation, it doesn’t cover everything. There are many configurable options and features in CRM Analytics and Einstein Discovery that you can utilize to go beyond this basic example.
To keep our example relatively simple, we will imagine that the Pelican sales and service teams focus on three segments of customers – small, medium, and large. Within each segment, there are certain business rules that need to be applied in order to derive segment-specific insights and apply appropriate actionable variables (e.g. design services are only offered to small customers). Therefore, each segment needs a slightly different set of training data prior to deploying the respective model to an object in Salesforce. This will ensure when a user is looking at a customer record, the model is making predictions and recommendations specific to the segment of that record.
For the purposes of this article, I am assuming you already have some data in CRM Analytics. This dataset could come from a single object or multiple sources (including data outside of Salesforce). You can see a few rows from our example dataset for this walk-through in image number one below. Notice the Stage column – that is the outcome variable we want to maximize in this model (Stage = Closed Won). You will also see the customer fleet size categorical variable, fleet – Small, Medium, and Large. That is the variable we will use for filtering and segmenting our models in Einstein Discovery.

Create Datasets
Step one begins with a recipe that creates three subsets of the main dataset. These three datasets will be used to train a model for each of the three respective segments (all three focused on maximizing the same outcome). As you can see in the image below, we use a simple recipe filter to create a dataset that contains the records which match that segment. In this image, I have selected the “Small Fleet” node in the recipe to show the filter for that segment.

Next up, as shown below in image number three, we add a transform on the recipe that drops columns that are not appropriate for that segment. The transforms could be lots of things – calculations, feature encoding, derived columns, etc. This is where you do any required pre-processing to perform feature engineering for your training dataset(s).

Create Einstein Discovery Story
Once the recipe runs successfully, we’ll have three datasets that are filtered to only the rows that match the recipe filter with appropriate transforms applied. We will then train a model in Einstein Discovery on each of these subsets maximizing the exact same outcome variable (Stage). This is shown below in images four and five.


Deploy Einstein Discovery Model
After we have created the three Einstein Discovery Stories, then it is time to deploy the models with the Einstein Discovery model deployment wizard. In order to achieve simplicity and maintainability, we want to deploy our three models to the same prediction definition, as shown in image six. This allows you to easily apply multiple models to a common prediction field in an object. Deploying to a single prediction definition simplifies the usage of multiple models for business process automation such as Salesforce Flows, Next Best Action, etc.

Next, we can select actionable variables which might be specific to each segment as we deploy them. This will provide unique prescriptive recommendations to the users for each segment.

The next step in the Einstein Discovery model deployment wizard is to add a condition that will focus this model on the correct segment (image eight).

Once that is done, you can verify in Model Manager that you have one Prediction Definition which is connected to all three of your models. See image nine below.

Show results in the target object
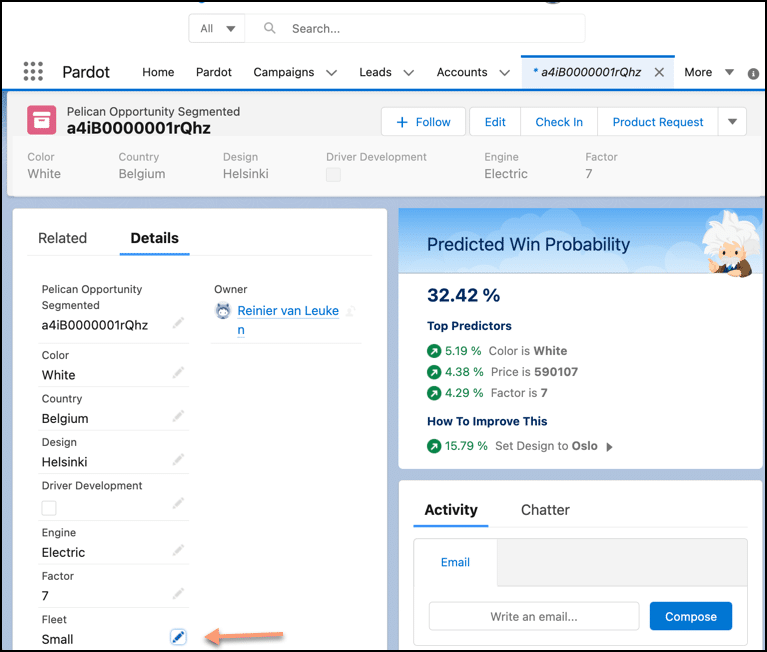
The last step – configure the Einstein Discovery Lighting Component in your target Salesforce object. If you then open a record as shown below in the images below, you will notice that the appropriate model is being applied to the records (based on whatever your segment criteria happens to be). And voila, you have deployed segment-specific models to your CRM data so that users will be empowered with relevant predictions, insights, and recommendations!


** Special thanks to my brilliant friend and colleague, Reinier van Leuken, for creating & sharing the Pelican examples.