Einstein Analytics: Data Sync Functionality Demystified!
If you are new to Salesforce or Einstein Analytics and you haven’t been in the trenches getting data curated for Einstein Analytics you might not have heard the term “Data Sync” even if you have heard of it you probably don’t fully understand it. Don’t fret I am the Product Manager for this feature and there are times I am not sure what magic is happening. It’s not that the concept is foreign, we have been staging data for analytics for as long as data warehouses have been around. The mystery is around how it is executed and what sort of methods can be used to make it more efficient.
Ok let’s start with the basics; Data Sync is a mechanism for establishing a link to an object in a data source (we call them connections facilitated by connectors in Einstein Analytics) that can be used to copy some or all of the data into Einstein Analytics. We have different Connectors that can be used to set up connections to applications and databases such as Snowflake, BigQuery, Redshift, Salesforce, Marketing Cloud and numerous others. Not all connectors are created equal, they have different features and limits so be sure to read the documentation for the ones you plan to leverage.
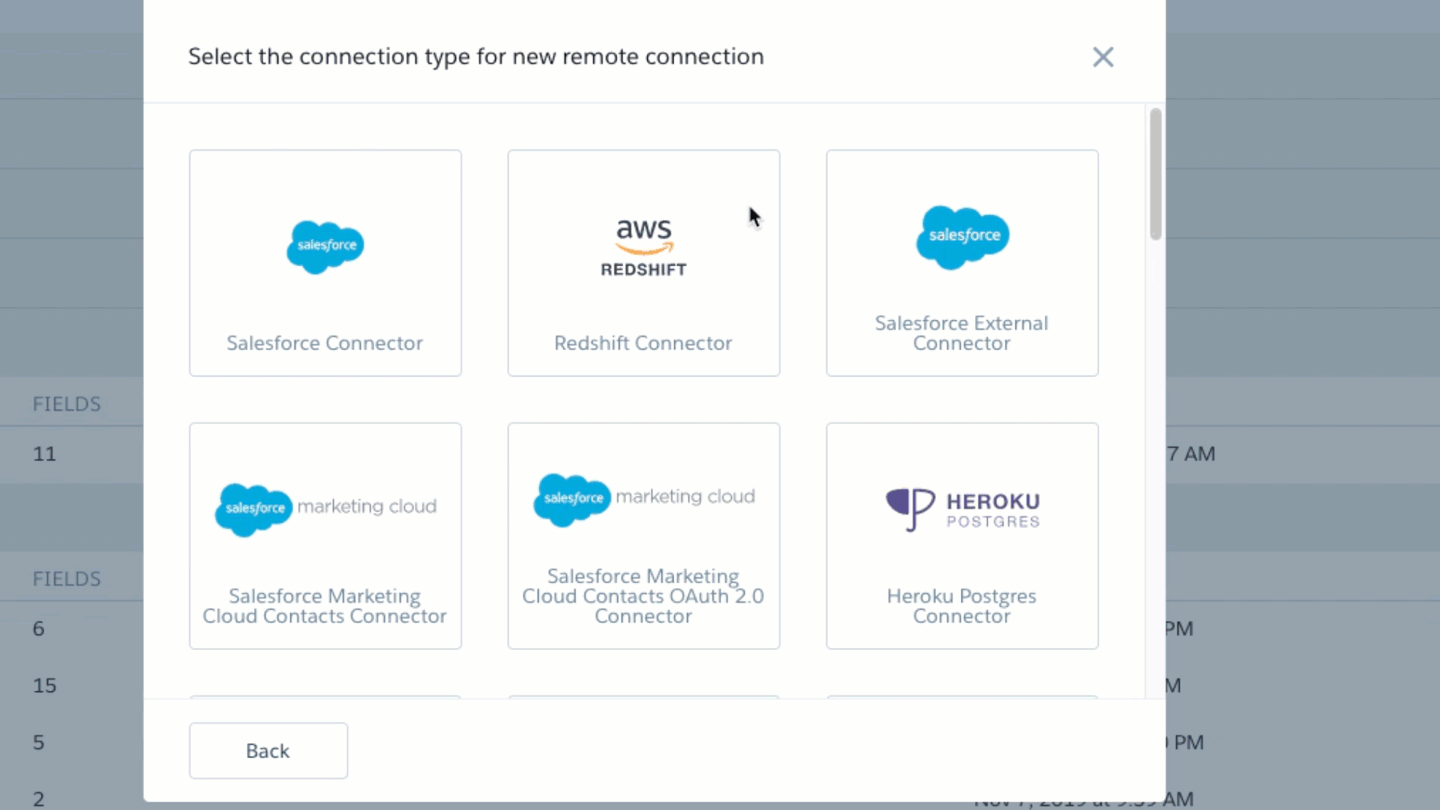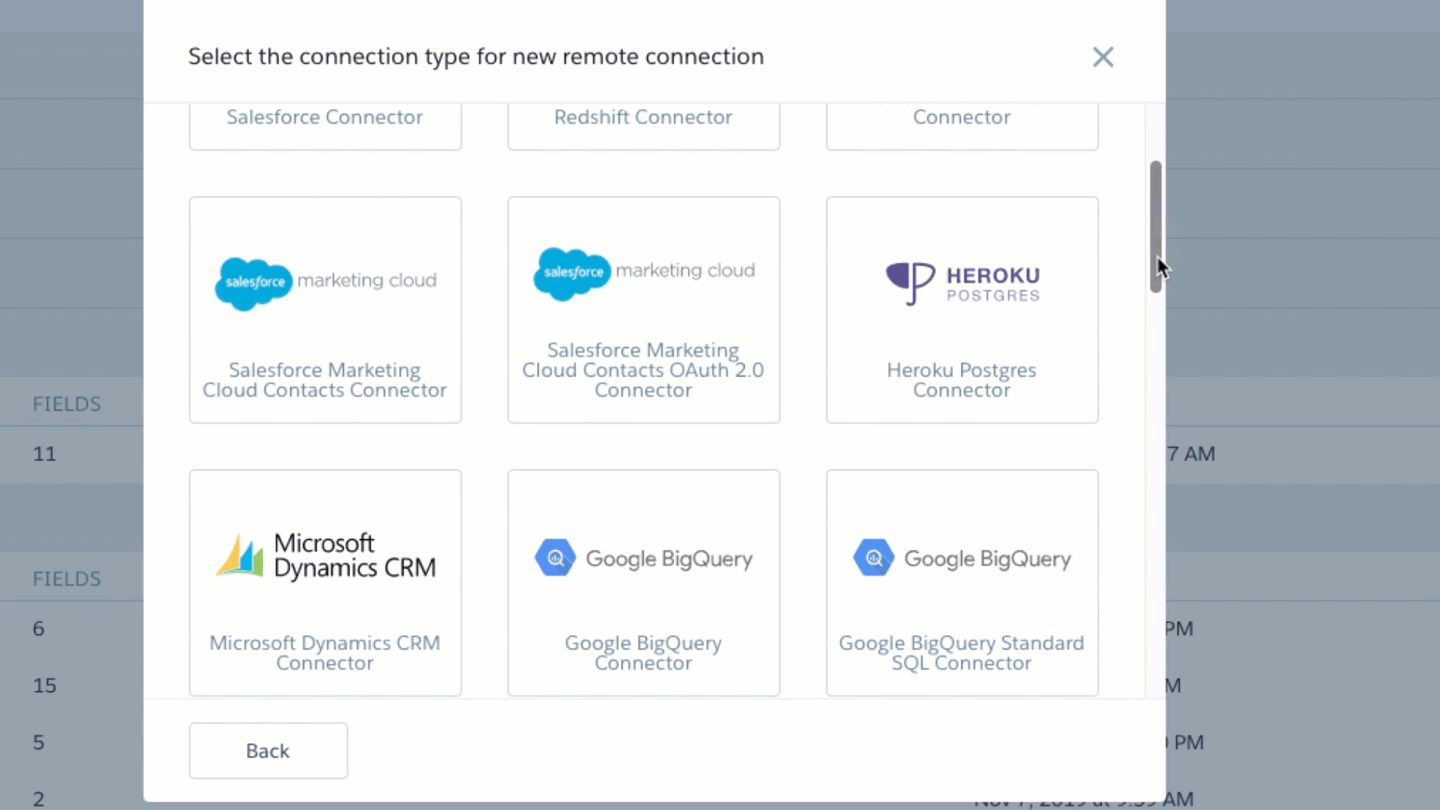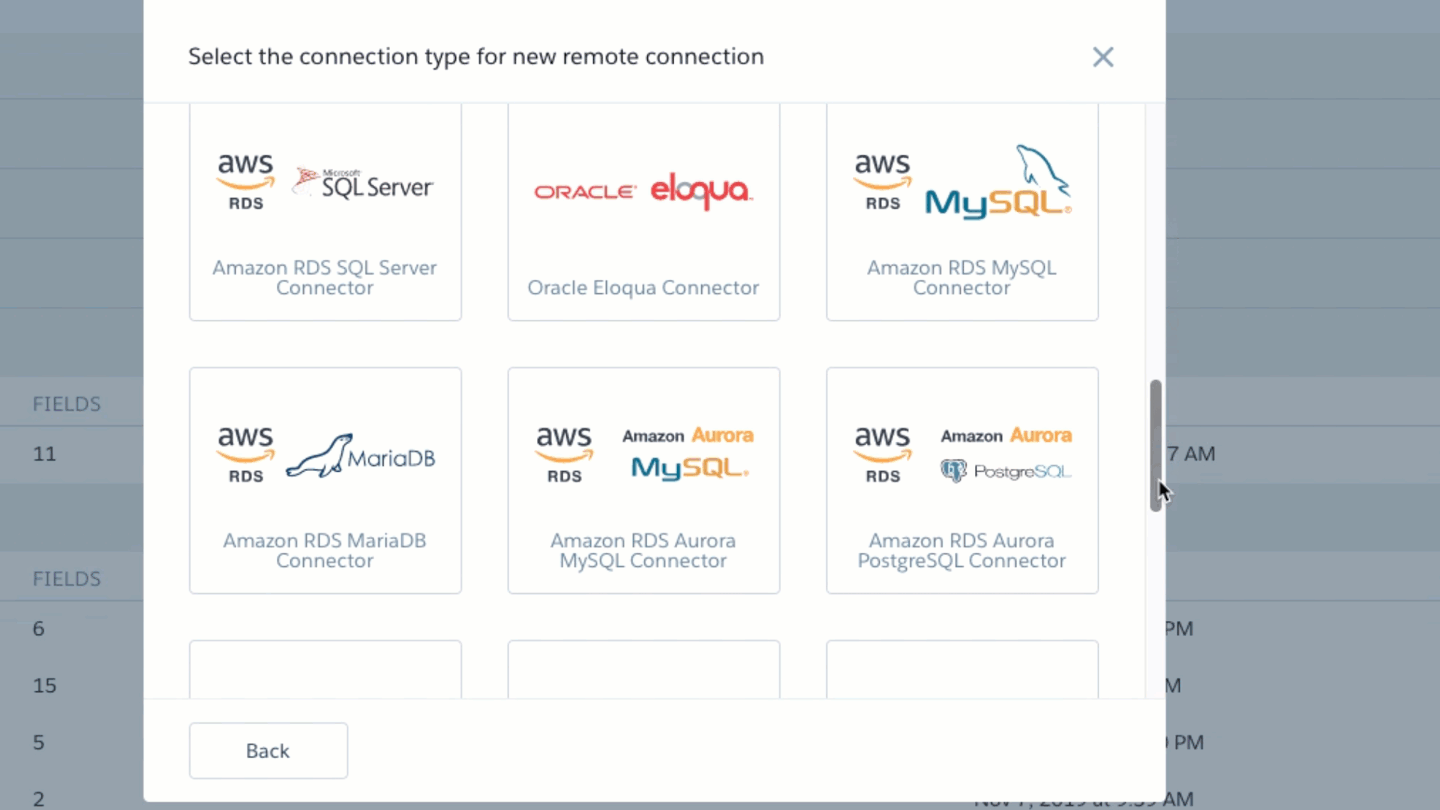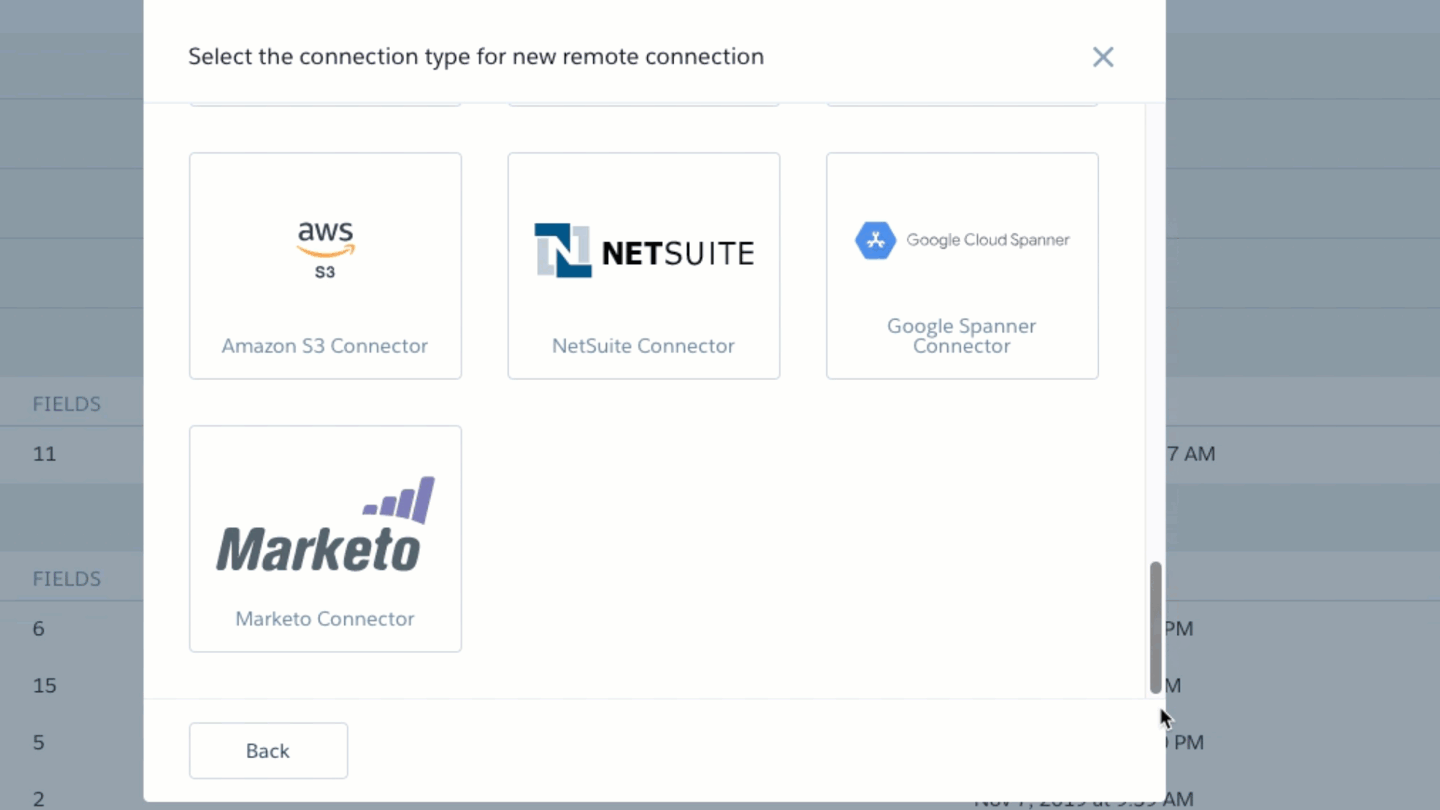
Salesforce Local (aka SFDC_Local) connections (the Salesforce Org that hosts the Einstein Analytics you are using) have particularly special capabilities when it comes to Data Sync. So it is important to consider the connection you are using when contemplating how to use a particular connection. Check out the documentation for more detailed information.
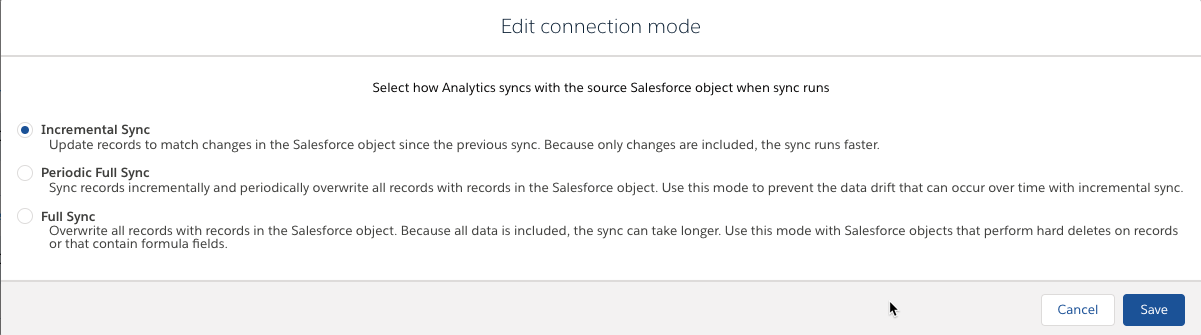
One of the more powerful capabilities for SFDC_Local is something called “Connection Mode” which for objects coming from the local Salesforce org allows for incremental load capabilities. In the future, we’ll dive into this topic in more detail, but for now, just understand objects capable of supporting incremental will load faster, therefore, decreasing the overall processing time and load on the system (win-win).
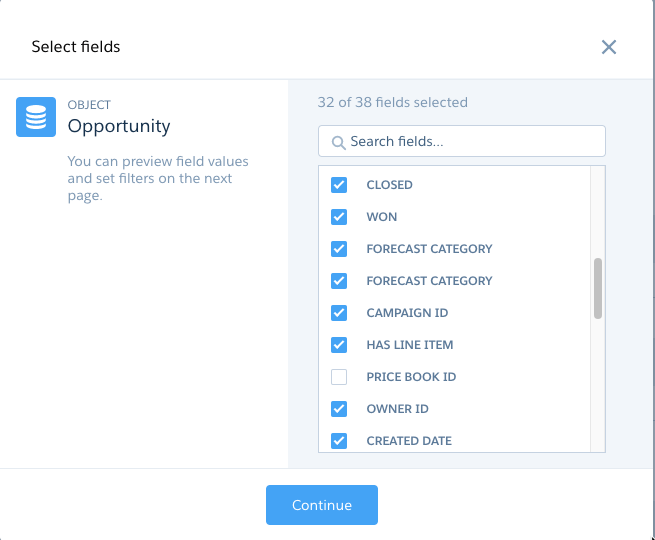
For Data Sync regardless of the connection a single object/table is set up at a time and the process involves using the connection to query the metadata of the database/application API to obtain field names and datatypes. We also pull back sample data to help evaluate if you are selecting what you really want.
You are using this step as a means of only bringing in relevant and needed fields to keep things simple and clean.
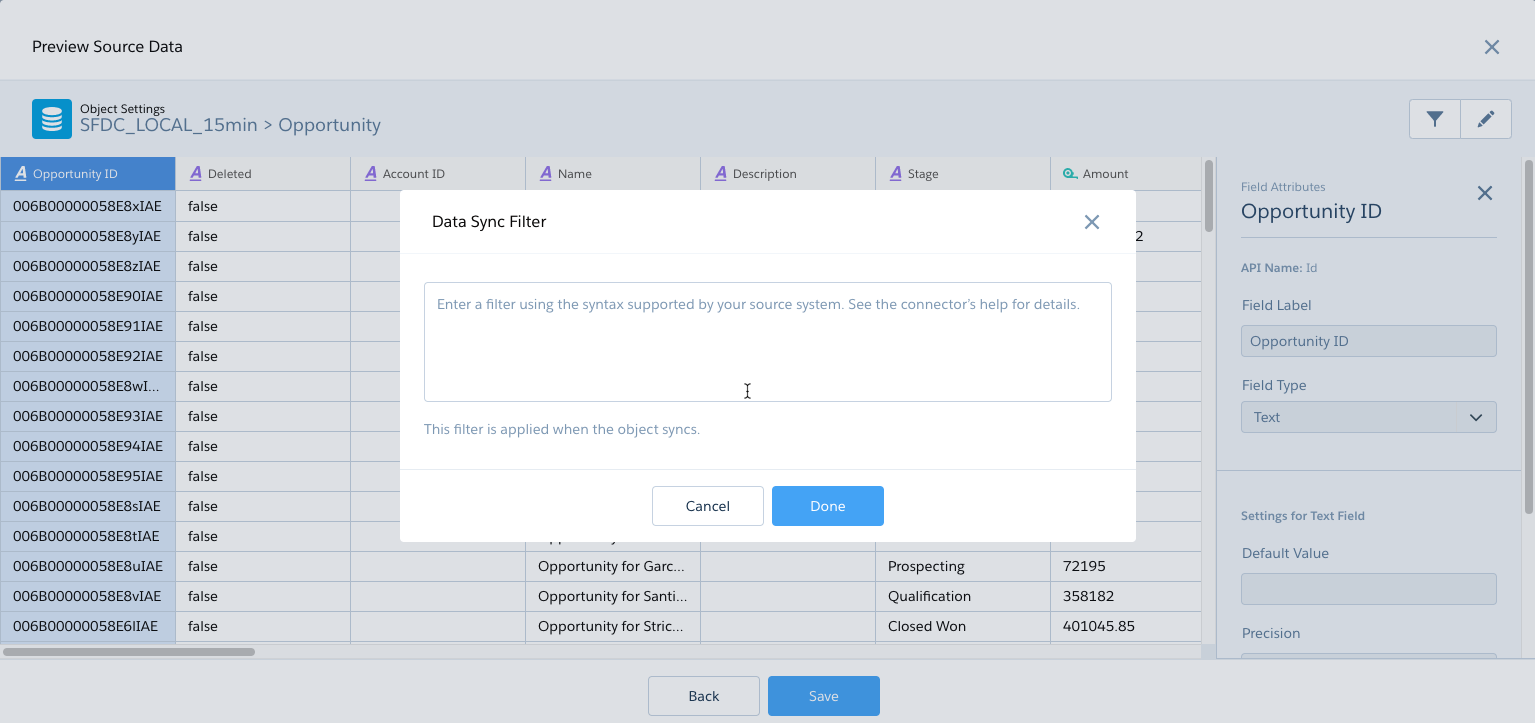
Recently we’ve also added Filters to the connectors that can support them so you can limit the data coming in rather than limiting it afterward of course if it makes sense to do so.
If a connector supports filtering we add a section to it’s documentation page identifying it as such and you will see the “filter icon” in the Preview Source Data page as well.
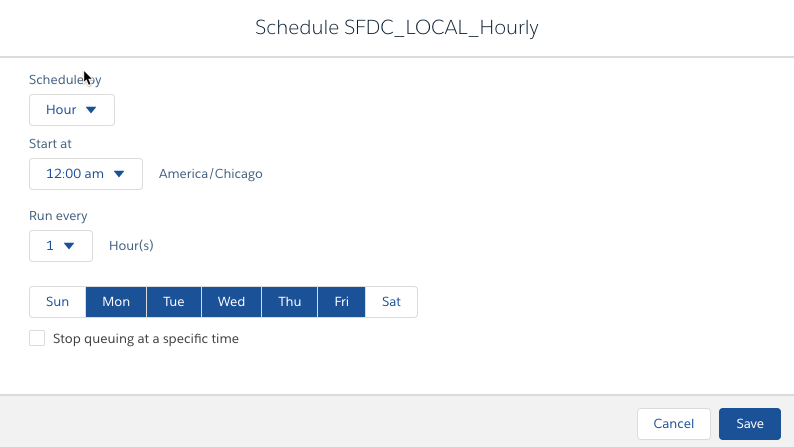
Ok, you have a connection and you have an object set up for Data Sync. Now it just magically stays in sync all the time … right … no it’s not that magical. We have to schedule Data Sync to run and that is done at a connection level. So you will want to pick the right time of day for refreshing the data in Einstein Analytics for the different connections you have. And with our scheduling capabilities, you can schedule up to every 15 minutes. But hold your horses bucko, just because we can schedule every 15 minutes doesn’t mean you should as your load may take 1 hour to run so we will be canceling jobs more than running them. This is the part I was talking about how stuff behind the scenes is getting “resolved” but you don’t see it unless something goes wrong.
A cool thing about the scheduling of Data Sync is that you can use it to drive your Recipes in Data Prep. So, if you make the Recipe’s schedule dependent on Data Sync, when Data Sync is done your Recipe runs and you have the latest and greatest data.
Oh and on the topic of an enhancement that we have done recently. In the past, you could have only 1 connection for your Salesforce Local. So everything ran every day or every hour … a bit painful. Well, we have added Connection Groups (up to 10 of them) that you can create so you can schedule 1 object for every 15 min, 5 for every hour, and 20 for once a week if you need to.
The way to do this same thing for non-Salesforce Local scenarios is to just create new connections since scheduling is done at that level.
Why do we even need to do this sync stuff, can’t we just pull it from the source when we need it? Well, the answer is yes you can in some cases, but in others, your operational teams will be quite irritated that your dashboards are impeding the operations of the business. Data Sync facilitates those cases where your data does not need to be up to the minute fresh for the cases where that is the requirement we have Salesforce Operational Reporting and also some new Direct Connectors for Salesforce and Snowflake that can be leveraged in Einstein Analytics.
One more topic that sometimes comes up related to Data Sync is that there are “limits”; Salesforce as a multi-tenant environment uses limits to manage and maintain expected service levels. So for Data Sync, we have some base limits such as the 100 objects; meaning no more than 100 objects can be set up for sync by default. If you hit this limit this is something we can discuss extending and we are examining if globally we might increase this. The other primary consideration is that we allow for 3 concurrent syncs to run at a time. So there is a need to set up a scheduling strategy to allow things to complete in a reasonable time without competing. See the documentation for additional limits.
Hope that helps illuminate the whole Data Sync topic or you all! Stay tuned as there is more to come on this front
Thanks Chris, for the post.
I have a question and a comment.
My question is why the AWS/RDS MySQL connector will not support the syncing of unsigned integer fields? I don’t know who is actually responsible for this connector, but our development team is not impressed and I’m getting tired of having to remind them to not us unsigned IDs, etc. in their MySQL tables. If this isn’t a Salesforce maintained connector, to whom would we elevate a change request and how would it get there?
My comment regards sync intervals. Yes, you can sync data every 15 minutes, but like many things in the software world, that is only if your licensing is at a certain level – I think 500 Einstein Analytics licenses. For us, that’s more licenses than employees and we do have a need for near real-time synching.
Christian Gurney
Director of Business Intelligence and Analytics
Mecum Auction, Inc.
Christian,
Yes I am the one responsible for the Connectors portion of the product. As you can imagine we don’t code every bit of code ourselves; which leaves us dependancies on third parties who choose to add support or not add support for certain datatypes. Well this is the case here in that the code does not support these unsigned int fields. We are pursuing alternatives to be able to bring these fields in and continue to lobby for the addition of these fields in the supported list. I have had your case (previously closed) associated to the work item my team has to attempt to resolve this so we can make sure you get updated when and if we can get past this topic.
As for the 15 minute scheduling topic; you are correct that this capability is in fact a feature of the Einstein Analytics Plus license. However this is something we have discretion on and have added the TIP to the documentation on how customers such as yourself can obtain this capability; simply log a case with support and I will receive an “override request” for approval. https://help.salesforce.com/articleView?id=bi_integrate_schedule_replication.htm&type=5
Well sorry I don’t have the first item addressed yet, but hopefully the second one will help ease some of the other stress.
Best wishes – Chris
Chris:
I appreciate the response and also the offer to look at a sync request interval change. I’ve asked our Dev Director to file the request on my behalf (all support tickets go through his group).
Thanks again for taking the time to answer my questions in this forum.
Christian Gurney
Director of Business Intelligence and Analytics’
Mecum Auction, Inc.
Chris:
An update. Our director of development discussed the situation with support and the member he spoke with continues to insist we have to have a 500 user license and wouldn’t/couldn’t forward a request. The support case number is 27750192, if you can help.
Christian Gurney
Director of Business Intelligence and Analytics’
Mecum Auction, Inc.
Hello, when migrating the dashboard, flows, recipes from org to org using change sets. How do you migrate SFDC_Local object connections. I have migrated everything successful except the connections. I have to manually compare side by side each connections from source org to target org. Any info on how to do this will be greatly appreciated. Thanks!
Hi Isabel, did u manage to find a solution for this.kindly let me know
Yes I also have this issue. I checked all the metadata I could find but I could not find the definition for the connection stored somewhere. How do we deploy this to other orgs? I hope we don’t have to manually click all those fields again for every sandbox?
Thank you
Hi Isabel,
Did you find a solution to this problem?
Cheers
Tim
I am facing the same issue as mentioned by Isabel.
is there any solution for this.
Hi Divya,
Did you manage to find a solution for this?
Cheers
Tim
Can you please let us know how many SFMC connectors can be added in EA.
I have couple of datasets connected with the databrick using Salesforce Connector. Now everytime they insert the data/file it shows in CRM Analytics in Data Manager. Now I want same to be displayed in the Data Manager.
We have both the License: CRM Analytics and Data Pipeline.
Can anyone please the suggest, Where the changes are needed?